Ravikumar Sharma
Technical consultantBen je bezig met het ontwerpen van schaalbare en efficiënte applicaties met MongoDB? Dan is een goed datamodel onmisbaar. Als NoSQL-database biedt MongoDB veel flexibiliteit in het structureren van je data. Door de juiste patronen te kiezen, kun je de prestaties en beheersbaarheid van je applicatie aanzienlijk verbeteren. In deze blog bespreken we 4 veelgebruikte technieken: het subset pattern, bucket pattern, extended reference pattern en het correct afhandelen van attributen.
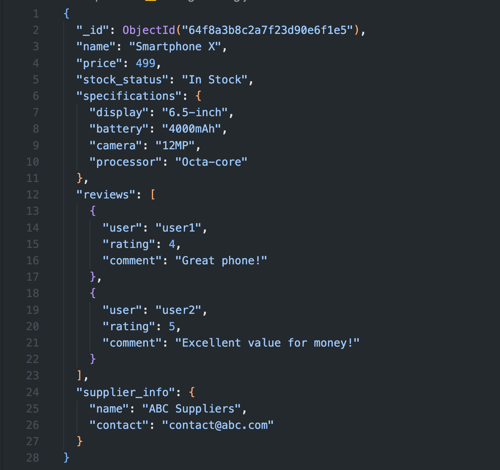
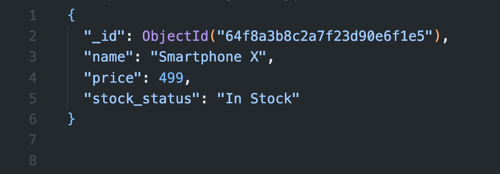
Als je werkt met documenten met veel data waarvan je meestal maar een klein deel nodig hebt, is het subset pattern erg handig. Denk aan een productcatalogus waarin elk product uitgebreide informatie bevat: specificaties, reviews, leveranciersinformatie en nog veel meer. Als de meeste queries alleen basisgegevens zoals de productnaam, prijs en voorraadstatus nodig hebben, plaats je die in een kleiner document.
Door het subset pattern toe te passen, blijven de belangrijkste details snel én gemakkelijk toegankelijk. De minder belangrijke informatie sla je apart op in een andere collectie. Zo verminder je het geheugengebruik, wat vooral erg is fijn als je veel opgevraagde velden moet indexeren.
Heb je indexes nodig op veelgebruikte velden? Dan is dit pattern effectief. MongoDB moet namelijk de volledige index in het geheugen houden. Door alleen de essentiële velden te indexeren in je subsetcollectie, bespaar je significant op geheugengebruik. Let op: je hebt een goede strategie nodig voor het synchroon houden van de subset- en detailcollecties.
| Voorbeeld voor | Voorbeeld na: |
|
|
|
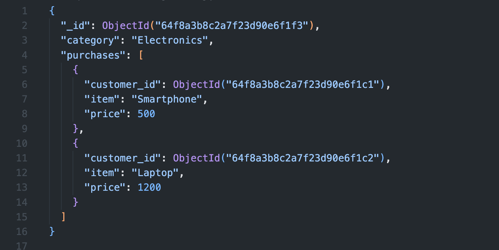
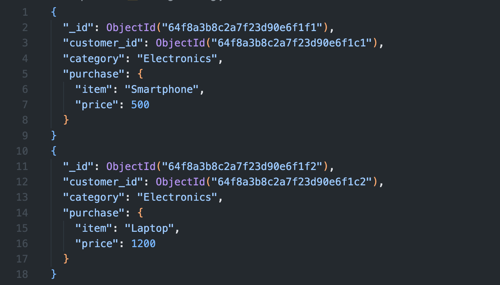
Heb je meerdere vergelijkbare datapunten die je kunt groeperen? Dan kun je het bucket pattern gebruiken om het aantal documenten te verminderen. In plaats van voor elk klein datapunt een apart document te maken, groepeer je deze in ‘buckets’ op basis van een vast attribuut, zoals een categorie of bereik.
De optimale bucket size hangt af van je use case. Te kleine buckets leiden tot te veel documenten en overhead, terwijl te grote buckets individuele updates inefficiënt maken. Een vuistregel is om buckets te maken die niet groter zijn dan 16MB (MongoDB's documentlimiet). Bij tijdreeksdata kun je bijvoorbeeld per dag of per uur bucketen, afhankelijk van je datavolume.
Op deze manier verminder je het aantal documenten dat MongoDB moet verwerken, waardoor het schrijven én lezen sneller gaat. In plaats van elke aankoop bijvoorbeeld in een apart document op te slaan, zet je alle aankopen uit een categorie bij elkaar in één document.
| Voorbeeld voor | Voorbeeld na: |
 |
|
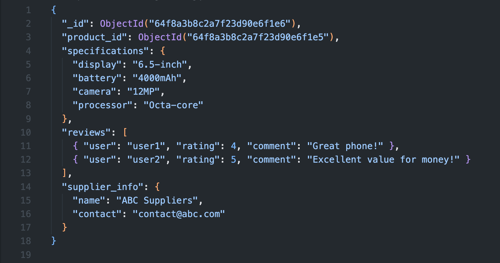
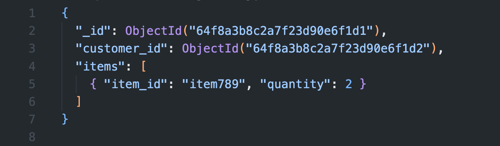
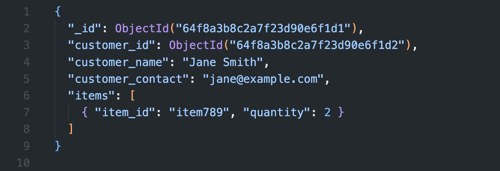
Het extended reference pattern helpt bij het vinden van de juiste balans tussen embedding en referencing. Met extended references kun je belangrijke data direct in een document opslaan om het aantal queries te verkleinen. Bij een orderdocument kun je dan belangrijke klantinformatie (zoals naam en contactgegevens) direct opnemen, in plaats van dat je het klant-ID of volledige klantprofiel eerst moet opslaan.
Dit pattern vereist wel een goed doordachte updatestrategie. Verandert de reference data? Dan moet je bepalen of en hoe je de extended references updatet. Kies daarom velden die relatief statisch zijn of accepteer eventuele inconsistenties voor een bepaalde tijd.
| Voorbeeld voor | Voorbeeld na: |
|
|
|
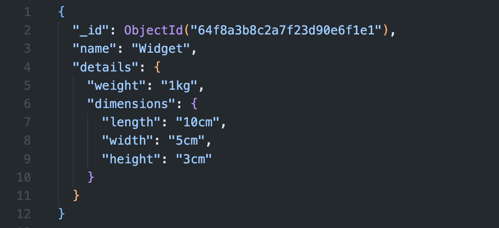
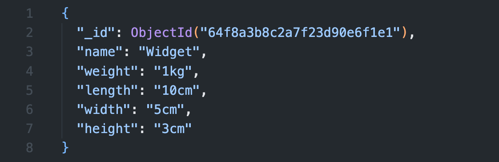
Het correct afhandelen van attributen is van groot belang bij het ontwerpen van je datamodel. MongoDB is schemaless, maar het blijft belangrijk om consistente conventies te volgen. Gebruik dus duidelijke namen, vermijd diep geneste structuren die queries vertragen én maak optimaal gebruik van MongoDB's indexeringsmogelijkheden.
| Voorbeeld voor | Voorbeeld na: |
|
|
|

MongoDB biedt veel flexibiliteit in data modeling, maar dit betekent ook dat je de juiste keuzes moet maken. We zetten de belangrijkste overwegingen voor je op een rij:
- Subset pattern: maakt veelgebruikte data eenvoudig toegankelijk.
- Bucket pattern: helpt bij het efficiënt opslaan van tijdreeksdata.
- Extended reference pattern: biedt de juiste balans tussen embedding en referencing voor betere prestaties.
- Correct beheren van attributen: houdt het datamodel flexibel maar consistent.
Elk patroon heeft zijn eigen sterke punten. De kunst is om te weten wanneer je welk patroon het beste kunt toepassen. Door deze best practices te volgen, zorg je ervoor dat je applicatie optimaal presteert, zelfs als je data blijft groeien.
Heb je vragen over MongoDB data modeling? Of wil je meer weten over onze aanpak? Onze MongoDB-gecertificeerde developers hebben ruime ervaring met het implementeren van deze patterns in complexe applicaties en denken graag met je mee over de beste aanpak voor jouw specifieke situatie. Neem contact op met onze experts. Neem contact op met onze experts.
Contact